Yikes, more character encoding problems! I am trying to format some demo data in a spread sheet for a visualization I am using. I often use the technique of saving an “excel” type document as CSV and then using python to convert the CSV to a JSON file to read in the browser. (Clearly this is a non optimal tool chain, but I usually don’t have the .xlsx file changing and so just run through it once).
Today, however, I attempted to read a JSON object from a cell and ran into interesting trouble. I needed to capture annotations to the data at specific data points, for example at t = 5.2 sec, “car jumped off the ramp”. In the LibreOffice file I have entered something of this format in a cell:
{ “5.2” : ”Car jumped off the ramp!” , ”10.6” : ”Crossed the finish line” }
This looks like valid JSON to me and if I type something similar a JSON evaluator will confirm for me it is valid JSON:
{
"5.2":"Car jumped off the ramp!",
"10.6":"Crossed the finish line"
}
However, when parsing this in javascript using JSON.parse() (required because the python csv.DictReader followed by json.dumps() only creates one level deep of a json structure, so these complex cell contents are stored in a string), I got the following message:
Uncaught SyntaxError: Unexpected token “
Humm… does this font reveal to you the possible problem? Looks like a weird quote character and the JSON spec is pretty clear, a plain old double quote is needed.
The file is saved as UTF-8 and printed to the terminal (verified the terminal encoding is also UTF-8 using “echo $LANG”) my quotes now print as “\xe2\x80\x9c” for the first one and “\xe2\x80\x9d” for the subsequent ones, which correspond to the Unicode code points “\u201C” and “\u201D”, also know as “Left Double Quotation Mark” and “Right Double Quotation Mark”.
I was also able to confirm this by pasting the error message quote character into this online hex converter.
Turns out when editing the cell contents in LibreOffice (to adjust the format to something that *should* be valid JSON) my quotes were being auto corrected. You can disable this “feature” from the menu “Tools >> AutoCorrect Options…” by disabling the Double quotes Replace in the lower right of the dialog as shown below. 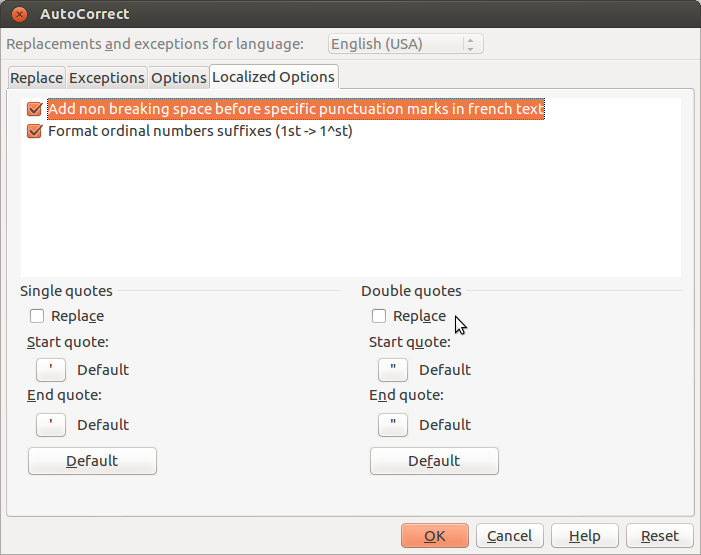
In case your source file wasn’t under your control, the following python can be used to replace a unicode character:
# replace Left Double Quote with "
fixedStr = brokenStr.decode('utf-8').replace(u"\u201c', "\"").encode('utf-8');
It also turns out that if you edit your cell contents in a different editor (like emacs) and then paste it in, the auto correction is not applied, which can make debugging a bit more confusing!
Lastly, I found the Unicode confusables site interesting, there are 15 confusable quote characters. So many!

