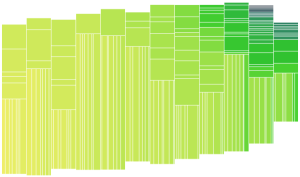
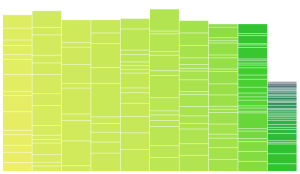
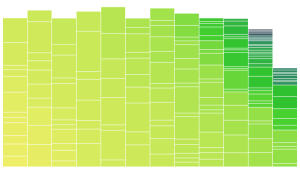
Continuing the work on the Color Prioritized Tree Map, I implemented variable column widths as a step towards making the tree map look more organic. The top picture here is uniform widths for reference and the one below introduced some variable widths, specifically I used a widths multiplier array of [2,3,4,2,5], which is then wrapped to apply a multiplier to the width of each column. This means the second column is 50% wider than the first etc.
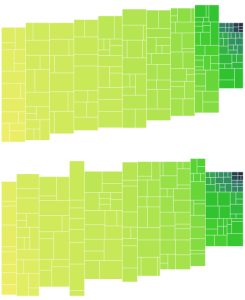
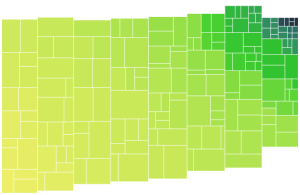
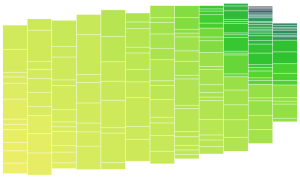
The column widths are assigned before the data is binned, the bin sizes are now equal height instead of equal area. Below is another example. Based on initial testing, the variable widths improve the image best when tweaked and evaluated by eye (since the data set and number of columns also affect the resulting shape). Overall, variable column widths were not as big a gain as I was hoping. Also since the columns are centered on a diagonal, the stepping appearance is retained. I guess introducing variable height would help! But I think the better approach is to look into ragged edges first.
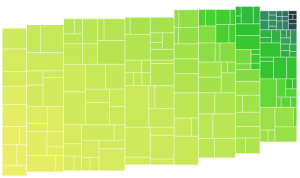
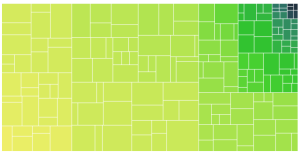
I also tested out a few other data sets, these ones are really lumpy:
I am still not sure what sort of data will be representative for the target application, but these data sets did stress the viz a bit and demonstrated that the following suspected issues are real:
- Very small areas erased by a white border: The border is implemented by subtracting a “margin” value from the desired length and width of each element and may result in invisible cells for very small areas. In practice these are so small as to be virtually invisible before, but I modified the code to not apply the white space if it will erase the data point for now.
- Bad data in the form of missing fields crashes the viz: This is corrected now handled by silently rejecting those data points.
- Giant elements overflow the column and go off the top of the user provided SVG: Elements with area greater than what should be in a column get put in a column anyway, in which case, the tree map can go off the top of the SVG. It probably makes sense to have some guidelines regarding number of columns based on the size of the largest data and the distribution. A related improvement would be to verify that we aren’t drawing outside the designated box and scaling everything down appropriately if we are to ensure we stay on the user provided SVG.